Research
Should Online Learning be Interleaved? Theory and Evidence from a Field Experiment
Under Major Revision at MIS Quarterly
Authors: Andy Tao Li, De Liu, Sean Xin Xu, Cheng Yi
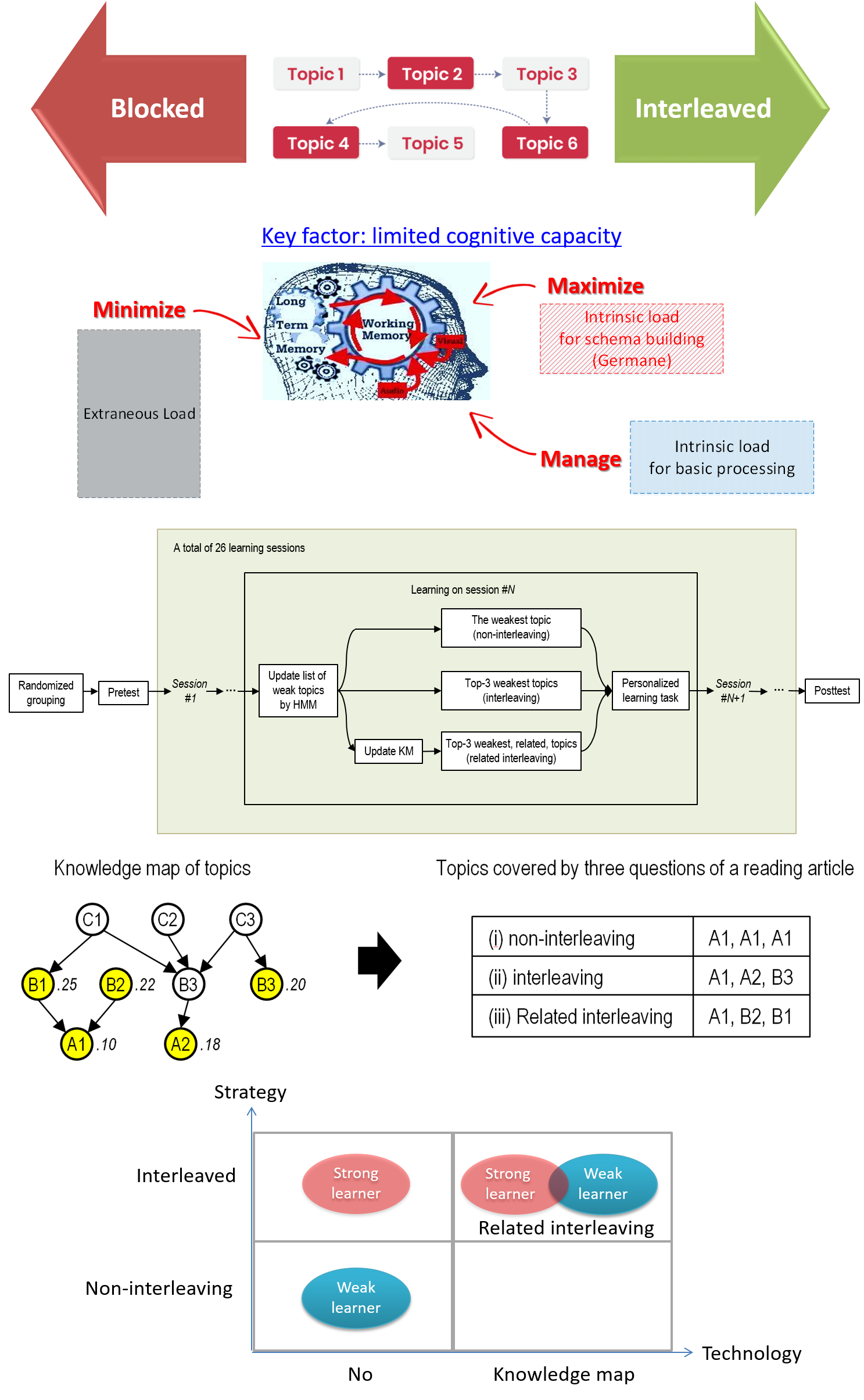
The rise of online personalized learning draws attention to the issue of how to sequence learning repetitions across multiple topics. Research thus far has shown mixed evidence in the relative effectiveness of the “non-interleaved” sequence design (i.e., focusing on one topic at a time in a learning session) and the “interleaved” sequence design (i.e., mixing different topics). From the lens of cognitive load theory, this study theorizes the effect of interleaving on learning performance and how such an effect may vary with learner type (i.e., weak versus strong learners) and the relatedness between interleaved topics. We designed and implemented a personalized learning system with three different sequence designs, namely, non-interleaving, interleaving, and related-interleaving. Results from a two-month field experiment at a middle school suggested that interleaved learning did not improve learning performance in general, but strong learners were more likely to benefit from interleaving than weak learners. We further found that increasing topic relatedness in interleaved learning improved learning performance, especially among weak learners. This study deepens our understanding of the mechanisms underlying the interleaving effect and its boundaries. It also demonstrates how interleaving can be implemented in a personalized online learning system by leveraging machine learning methods.
Re-engage low achievers: Effect of meaningful extrinsic rewards in gamified online learning
Reject and Resubmit at Management Science
Authors: Andy Tao Li, De Liu, Sean Xin Xu
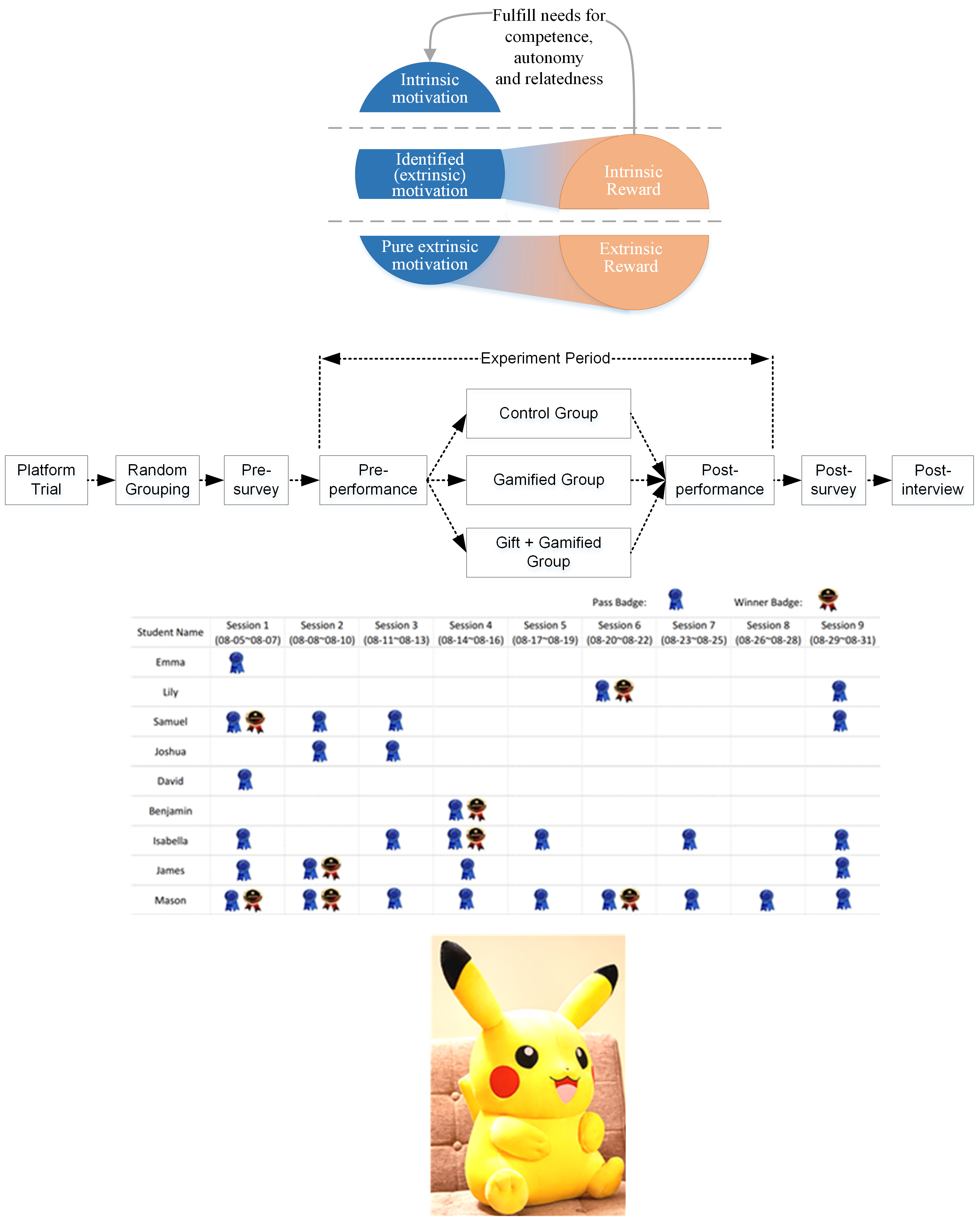
Many online learning platforms rely on voluntary participation, exacerbating the participation and performance gaps between high and low achievers. The latter often lack motivation to participate in such platforms, nullifying many gamification–based engagement measures that are conditional on participation. To jump-start low achievers’ participation, we propose meaningful extrinsic rewards to combine with gamification measures and test such an idea in a large-scale field experiment with students in six middle schools. We show that meaningful extrinsic rewards complement gamification to improve low achievers’ participation rate and learning performance, reducing their performance gap with high achievers. Moreover, meaningful extrinsic rewards and gamification jointly enhance low achievers’ intrinsic motivation and induce an enduring positive effect. Our study clarifies the boundaries of the motivation crowding theory by highlighting that deliberately designed meaningful extrinsic rewards can crowd in intrinsic motivation for low achievers who otherwise may not participate.
When does the platform tell you the truth? Optimal information provision with service differentiation
Authors: Andy Tao Li, Jie Zheng
In preparation to submit to Information Systems Research
Information is one of the most important channels in business decision making, and a platform can manage information disclosed to consumers in order to maximize its profit. In this paper, we analyze the information announcement strategy for an on-demand platform with service differentiation, in which the platform provides not only the standard service with stochastic stock-out risk, but also a more profitable guaranteed service. Consumers' preferences can be influenced by the service availability information announced by the platform. Thus, designing a state-contingent probabilistic disclosure strategy via a Bayesian persuasion approach will be optimal for the platform to boost its profit in both short-run and long-run. This is because the strategy allows the platform to announce a higher stock-out rate of the stochastic service which could persuade more customers to adopt the guaranteed service. By fully characterizing the conditions under which the platform discloses full, partial, and no information, respectively, we conduct analyses on the consequences for the platform's profit, consumer surplus, and social welfare. Investigating the impact of two complementary policies -- transparency policy and accessibility policy -- this study reveals that these two policies, aiming to subsidize consumer surplus at the cost of platform's profit, have very narrow feasible regions, beyond which they could backfire, causing further negative effects to social welfare. Our study has important policy implications for regulators, and provides a better understanding of the information-manipulation incentive in an on-demand platform of differentiated services with information asymmetry between the platform and consumers.
Design Challenge Levels in Online Learning:Insights from a Large-Scale Field Experiment
In preparation to submit to MIS Quarterly
(ICIS 2020 Best Paper Nominee)
Authors: Andy Tao Li, De Liu, Sean Xin Xu
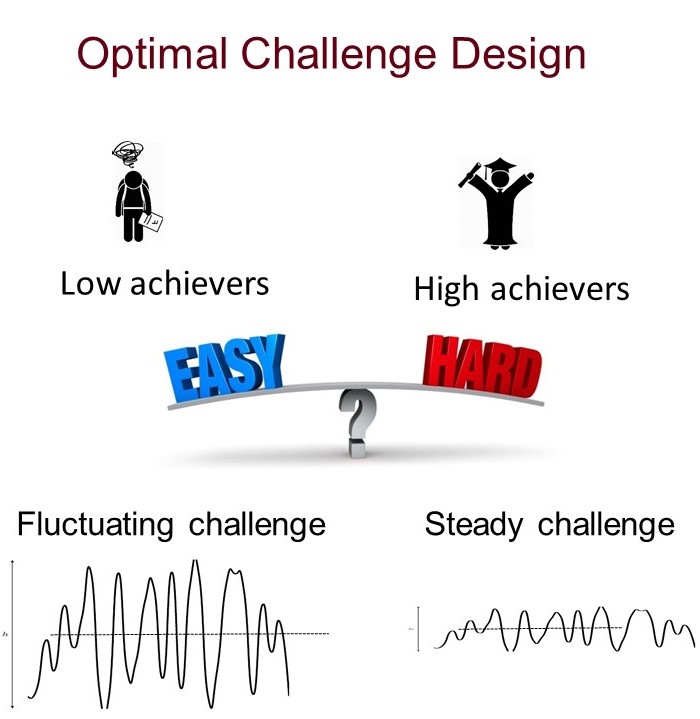
The existing adaptive learning focuses on detecting and mitigating knowledge gaps but has paid scant attention to the issue of regulating the challenge levels for learners. The latter issue is especially relevant when it comes to design a sequence of remedial exercises for learners. Insights from flow theory suggest that learners would be more engaged if their perceived challenges match their abilities. Despite these theoretical predictions, there are gaps in terms of how to administrate the desirable level of challenge in each exercise, how to evolve the challenge level over a sequence of exercises along with dynamic learning progress, and whether it pays to do so despite the fact that one may not perfectly control the level of challenge. We designed a personalized online learning system and conducted a field experiment at seven middle schools. From a static view, the optimal challenge level is heterogeneous and contingent on learners’ preparations: low achievers benefit more from low challenges relative to high challenges, while high achievers’ performances are insensitive to the challenge level. From a dynamic view, the steady challenge outperforms the fluctuating challenge, and this pattern holds for both low and high achievers.
Self-selection toward Polarization in Online Learning
In preparation for submission
Authors: Andy Tao Li, Alex Chong Wang, Sean Xin Xu, Michael Xiaoquan Zhang
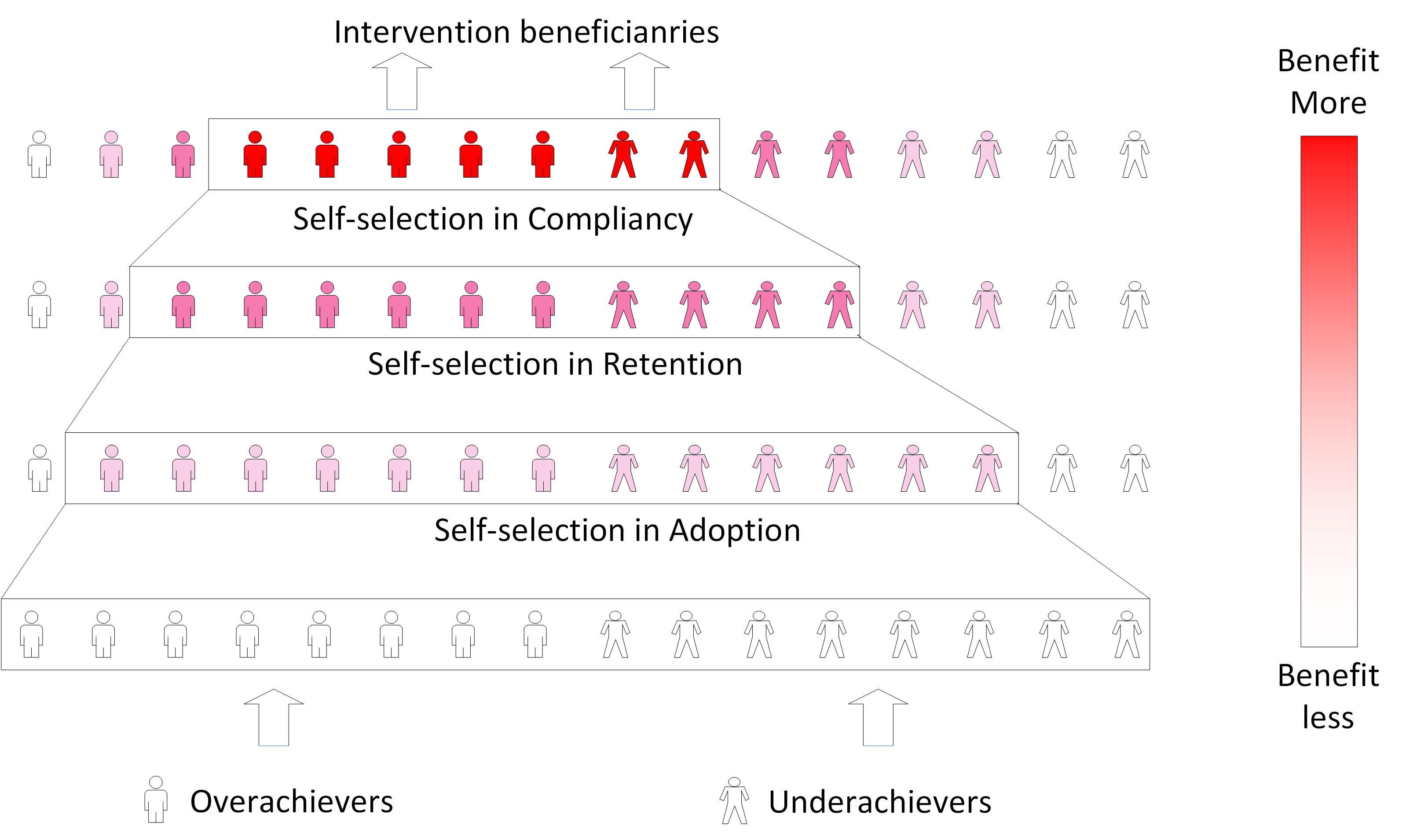
The Internet empowers educators to extend and enhance the learning experience outside the classroom. However, self-selection in online learning may lead to unintended consequences. In a field experiment carried out at a major university in Hong Kong, it is found that access to online learning materials led to polarization in learning outcomes as a result of self-selection in system usage. Enforcing learning path through a behavior nudge function strengthened self-selection and enlarged performance disparities in the final exam. Despite equal access provided by online learning systems, which leads to the belief of democratizing education, the experiment results highlight that online education may result in polarization, and it is challenging to correct self-selection in the online environment.













